Earlier this week I was doing some reverse engineering and confirmation of behaviour for a USB tool. I got wireshark to sniff the traffic, (Not going into that here, it’s relatively straightforward and documented enough on the web to get by) but as it’s a vendor specific protocol, it was just lots of bytes.
I was decoding them by hand, and then copying and pasting into a python script (I had pretty good sources of what all the bytes meant, I just had no good way of visualising the stream, which is where wireshark and this post comes in)
I have written a custom wireshark dissector before, but I wasn’t super happy with the mechanism. I have been doing some work with Lua in my dayjob, and had read that wireshark supported dissector plugins could be written in Lua now. Seemed like a better/easier/more flexible approach.
I got to work, following these (somewhat) helpful resources:
These were all generally very helpful, but there two things I wrestled with, that I didn’t feel were at all well described. From here on out, I’m going to assume that you know what’s going on, and just need help with things that are not covered in any of the earlier links.
Little Endian
You declare ProtoField’s as just uint8, uint16, uint32. This is fine and sane. But there’s a few ways of working with it when you add it to the tree.
f.f_myfield = ProtoField.uint32("myproto.myfield", "My Field", base.HEX)
-- snip --
mytree:add_le(f.f_myfield, buffer(offset, 4) |
f.f_myfield = ProtoField.uint32("myproto.myfield", "My Field", base.HEX)
-- snip --
mytree:add_le(f.f_myfield, buffer(offset, 4)
This way works very well, selecting “myfield” in the packet view correctly highlights the relevant bytes. But say you want to get the value, to add to the info column for instance, you might do this.. (if you read the api guide well enough)
local val = buffer(offset, 4):le_uint()
-- normal add, we've done the LE conversion
-- if you don't do :le_uint() above, and do a :add_le() below,
-- the info column will show the backwards endian value!
mytree:add(f.f_myfield, val)
pinfo.cols["info"]:append(string.format(" magicfield=%d", val)) |
local val = buffer(offset, 4):le_uint()
-- normal add, we've done the LE conversion
-- if you don't do :le_uint() above, and do a :add_le() below,
-- the info column will show the backwards endian value!
mytree:add(f.f_myfield, val)
pinfo.cols["info"]:append(string.format(" magicfield=%d", val))
At first glance, this works too. The Info Column shows the right value, the tree view shows the right value. BUT clicking on the tree view doesn’t highlight the bytes.
Here’s how to do it properly:
local val = buffer(offset, 4)
mytree:add_le()(f.f_myfield, val)
pinfo.cols["info"]:append(string.format(" magicfield=%d", val:le_uint())) |
local val = buffer(offset, 4)
mytree:add_le()(f.f_myfield, val)
pinfo.cols["info"]:append(string.format(" magicfield=%d", val:le_uint()))
Ok, a little fiddly, but you would probably get there in the end.
Reading existing USB properties
The docs talk about doing something like:
local f_something = Field.new("tcp.port") |
local f_something = Field.new("tcp.port")
Except, I didn’t find anywhere that described what magic strings were available. I tried using the values available in the display filter box, like, “bEndpointAddress” but never got anywhere. One of the samples led me to this tidbit:
local fields = { all_field_infos() }
for ix, finfo in ipairs(fields) do
print(string.format("ix=%d, finfo.name = %s, finfo.value=%s", ix, finfo.name, getstring(finfo)))
end |
local fields = { all_field_infos() }
for ix, finfo in ipairs(fields) do
print(string.format("ix=%d, finfo.name = %s, finfo.value=%s", ix, finfo.name, getstring(finfo)))
end
When you click on a packet, this will dump lots to the console, and you can hopefully work out the magic values you need!
Synchronising packets
TCP streams are easy, you have sequence ids to correlate things. USB isn’t quite the same. You can see the “URB” has two frames, from host to device and device to host, which are in sync, but for the very common case of writing to an OUT endpoint, and getting a response on an IN endpoint, you don’t get any magical help.
I found a way of doing this, but it’s not ideal, and tends to mess up the display in wireshark if you click on packets in reverse order. This is because I just set a state variable in the dissector when I parsed the OUT packet, and check it when I parse the IN packet. It works, but it was less that ideal. Sometimes you need to click forwards through packets again. Sometimes the tree view would show the right values too, but the info column would be busted. Probably doing something wrong somewhere, but hard to know what.
Actually hooking it up
Finally, and the most frustrating, was how to actually hook it up! The demos, all being TCP related, just do:
the_table = DissectorTable.get("udp.port")
the_table:add(9999, my_protocol) |
the_table = DissectorTable.get("udp.port")
the_table:add(9999, my_protocol)
Ok, well and good, but how on earth do I register a USB dissector? You need to register it by the class which is sort of ok, but good luck having dissectors for multiple vendor specific classes. I didn’t see a way of adding a dissector based on the VID:PID, though I think that would be very useful.
usb_table = DissectorTable.get("usb.bulk")
-- this is the vendor specific class, which is how the usb.bulk table is arranged.
usb_table:add(0xff, my_proto)
-- this is the unknown class, which is what shows up with some usb tools?!
usb_table:add(0xffff, my_proto)
Update 2013-Jan-16One of the sigrok developers got the vid/pid matching working, in another example of a lua plugin.
This skims over a lot, but it should help.
Final working code:
I’ve totally glossed over exactly _what_ or _why_ I was decoding vendor specific usb classes. That’s a topic for another day :)
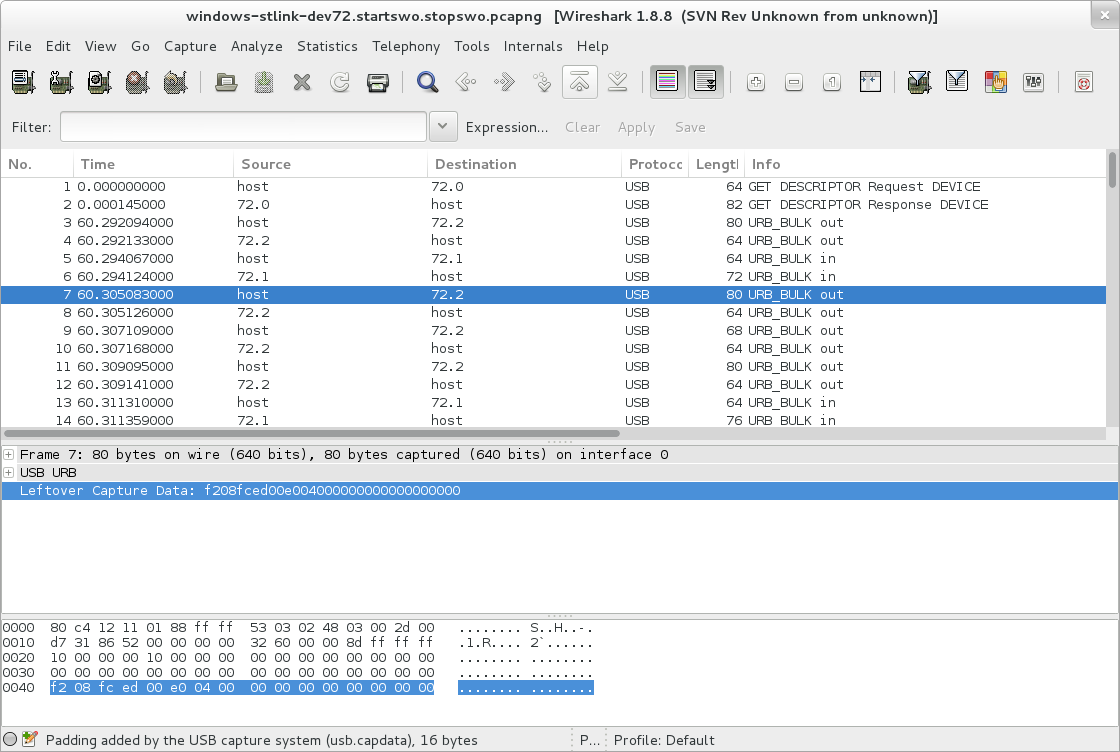
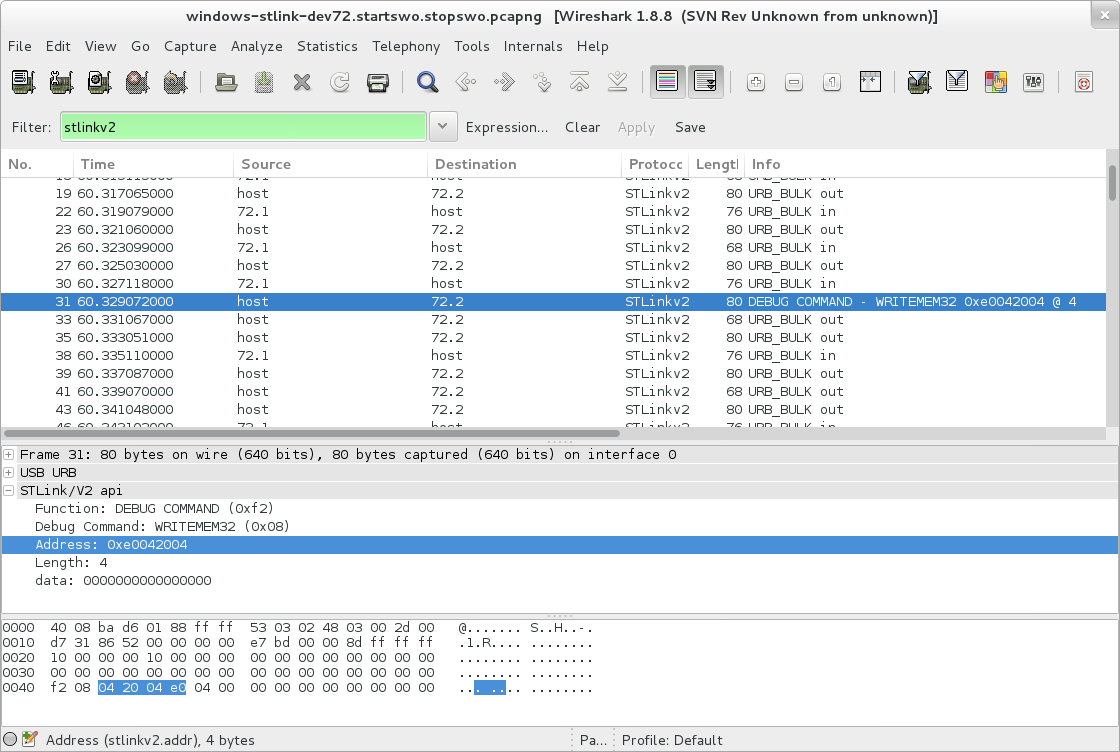
Here’s some pictures though
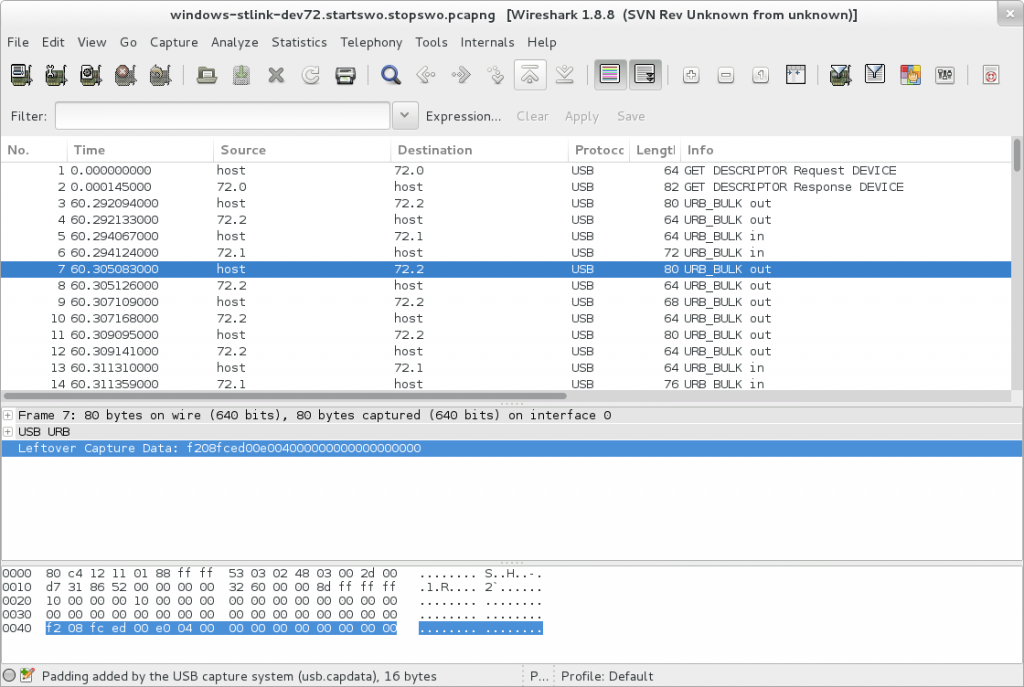
How it looks before you write a plugin.
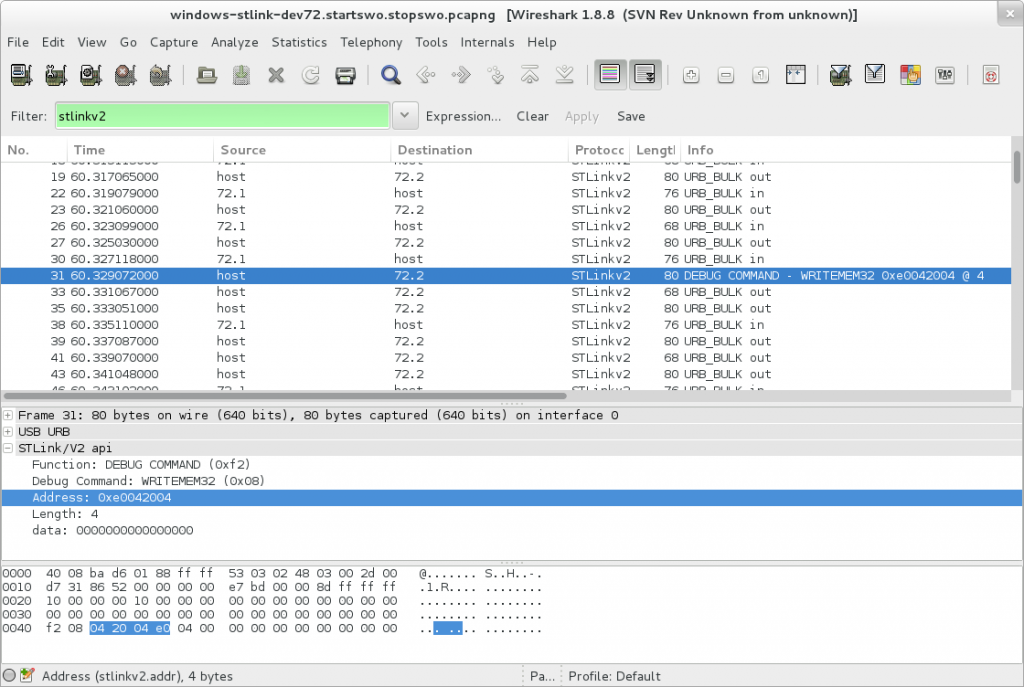
With the plugin, note that the info column isn’t always showing the proper values. No idea why. wireshark’s weird
PS: How about that title! linkbait to the max! keywords to the rescue! (or at least, the ones I had tried searching for)